
How I Made Random Category Elimination
First published: Monday June 21st, 2021
The Idea
The idea of a randomized version of my Category Elimination series is not a particular new idea. It's actually something I've wanted to do for almost two years now, however it was always impossible to achieve.
For starters, the existing random text quiz feature at the time didn't allow manual mode, so I would have to style everything with CSS. Not ideal, but doable. The biggest problem was that the random function selected entriely random answers, which meant selecting groups of 5 related answers was completely impossible.
This changed with the invention of "Random Group" on January 1st 2020. This new feature I added to JetPunk allowed for the possibility of random groups of answers to be selected, instead of just random answers. Some of my favourite Random Group quizzes are:
1. World Map with Random Merged Countries (I know, my own quiz, shameful but I love it)
2. Random Geographic Groups of Five
3. Find The Mystery City Using Color Clues - Randomized
These are all quizzes which are only possible because of the Random Group quiz mode of text quizzes.
Back to Category Elimination. It was looking like "Random Group" could solve the issue we were having before, since we can now select groups of 5 answers, each would correspond to a set of categories like the original series. However, we still had a couple problems to try and sort out:
1. Manual mode is still not available, so how would we set up triggers? (The cells hiding before you've answered the previous category)
2. The answers would still be from a finite set of categories. This means playing it a lot, you'd eventually hit the same sets of categories.
Starting with number 2, this wasn't a blocking issue per se, since other quizzes like (2) from above use a finite set of answers, despite there being infinite groups of five you could choose based on some arbitrary parameter. But unlike (1) and (3), where getting the same answers again and again doesn't impact enjoyability, it's still problematic to have the same categories every time.
The bigger issue, in fact, is that of number 1. After all, if users could see all 5 categories at once, the quiz becomes a lot easier. Let's take an example:
If the first 3 categories of a flag elimination are flags with "white", "blue" and "red". Going with the categories hidden, you might end up guessing 3 separate flags, making for a more fun, interesting and enjoyable experience. If you could see all 3 (and the further 2) at once, you would instantly guess somewhere like UK or USA, which satisfies all 3 clues. This felt like it completely defeated the enjoyment of Category Elimination, and so we were at another dead end.
It would take more than a year until I decided I was going to "hard-code" the Random Category Elimination into the website, so that it satisfied all the properties I wanted. This gave me much greater flexibility, but did not provide the community with any ability to create their own variations unfortunately (and I'll explain why later).
So after 2 years, we now have an idea and a means, I just needed to do all the laborious effort to actually make it.
Building up the Data
The first step, was data. Category Elimination has always relied on a large bank of data behind it, which I used to manually filter using Google Sheets and work out, generally layering categories on top of each other until I have 3-10 items left at the end, at which point I would try and get creative to ensure I could find a category which left only a single valid answer, but that might have multiple possible answers on its own. By that, I mean not choosing a category like "Countries with less than 1000 people", since this category alone has a single answer, and so requires no knowledge from the other 4 categories to complete.
Over time, I may have not fully stuck with that premise, but I tried my best to ensure the quizzes remained enjoyable.
This was where my first concern came in with the data. The plan was to feed JetPunk with a list of categories, each with a list of valid answers. For example, "Countries with Red on their flag" or "Countries with more than 10 million people". I could then use that to create the quiz... somehow.
From a data perspective, I would have to "feed" the algorithm with enough data that the game was not only possible, but enjoyable. I started with simple categories, and in the end I stuck with simple categories. It generally seemed best to keep generic categories, and ensure no particular category had too few possible countries, since this would defeat the aim of the original series.
Much of the data was pooled from my original spreadsheet used for Category Elimination, with some updates of the population and such. Another goal was to avoid association with capital cities; you see, I wanted to keep the original linguistic structure of Category Elimination. For example take a look at Orange of Countries #1:

From this you can see there is a structure to the categories, You start with a statement, and then each following category is:
... <connector> <statement>
The connector was most often "in", "and" or "with". How would I be able to keep this structure when randomizing the categories entirely? Well, I had to be clever with my wording of categories. I decided that the first category of each set would be "Countries <statement>", and then the 4 remaining categories would be "... <statement>". So, I would have to word every category appropriately that it fits, e.g. "One word countries" doesn't fit, but rewording to "that are only one word" now works, since you get:
"Countries that are only one word"
"... that are only one word"
The first works well, the second also works when following another category, such as "Countries that border Russia".
Initial Tests and Algorithms
Now came the initial testing of the data I had first provided. This was where I had to prove to myself the concept would work. I began by writing a script which would:
1. Pick a random country
2. List all its possible categories from the data bank
3. Check every other country to see if any country matched all of its categories
This was important to do, since if you have a country with only 8 categories, and another country had those exact 8 categories as well (and possibly more), then it would be impossible to ever get that country, since selecting it as an answer would make it impossible to reduce down to a single answer.
The way to solve this problem was to add more and more categories, still keeping to the data requirements above, but also looking at the countries that were the same and trying to find a category that would separate them.
I got to a point where there were 5 pairs of countries left to separate and distinguish. One such pair was Ghana and Kenya. These had many similar characters, such as both over 10 million people, both had Red, Green and Black on their flag, both in Africa, both five letters long, both ending in "A". It seemed like it would be impossible to find a good category. In the end, I delved into maximum elevation, since Ghana sits at 880m, whereas Kenya sits at over 5,200m.
After doing this for all countries, I got to a point where every country's set of categories was unique.
Stage 1 complete!
Stage 2 was going to be more difficult, I now need to make this work for just 5 categories. What this meant was, for every country, finding a set of 5 categories for which it was the unique answer to. E.g. if Ghana was picked, we would have to include the maximum elevation clue, as otherwise Kenya would also be included.
The Breakthrough
After spending a few hours continuing to find data, as well as come up with more categories, and adjusting the values of old categories to make this possible. I got to the point where 194 countries had a possible set of 5, many of which had more than one set of 5 categories.
Stage 2 complete!
Now, I actually had to come up with an algorithm to find a random valid set of 5 each time, ensuring I satisfied as many internal objectives as possible, including:
1. Choosing a random country should output 5 categories which make said country unique
2. The selected categories should have a nice "curve" to their numbers (I'll explain shortly)
3. The categories can't be trivial (e.g. Countries containing "K", "E", "N", "Y" and "A" as the 5 categories for Kenya)
And so, after some trial and error, I came up with a basic algorithm that I felt should work:
- Pick a random country
- Retrieve all categories for this country
- Count the number of countries which match each category, and find the mean average value
- Pick a random first category which leaves at least the mean number left over
- Generate a list of countries that match this category
- Select a remaining category at random
- Count the countries matching all selected categories
- If this number has decreased by at least 2 and is more than 1, then use this category and go back to (5)
Else, discard this category and try again from (6)
- Continue until 5 categories are reached
- If the remaining category results in more than 1 matching country for those 5 categories, remove the last 2 categories and try again from (6)
This basic algorithm provides the general idea of what is currently used today. It filters through the categories until it finds a way to get down to 5 categories which work. This satisfies #1, as required, #2 ends up being fairly well satisfied as we select the first category to always have more than average number of countries remaining, and so naturally we start with a large-ish number, making the set of categories approachable, and it naturally decreases by at least 2 (and usually a lot more) to get down to one.
However, we have not satisifed the 3rd one, since this algorithm is not capable of making exceptions. we'll discuss this and how other special cases are dealt with next.
Note that in #2, by "curve" I mean the number of countries remaining after each category. E.g. if the first category contains 150 countries, then the second reduces that to 89, the third to 45, the fourth to 11 and the 5th to 1, that's a "nice" curve, since we start high, reduce at a steady rate and end at 1. An example of "bad" curve, would be starting at say 95, then dropping to 32, then to 30, then to 3 then to 1. Comparing these graphically, we get the following curves:
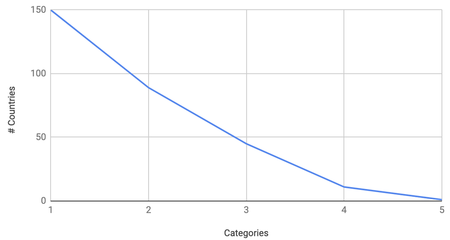
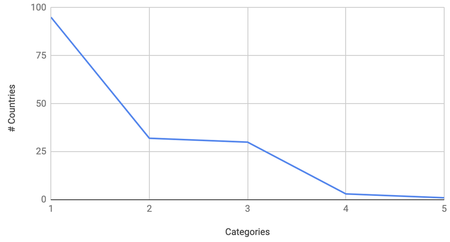
As you can see, on the left we have a smooth decreaing curve. It starts high and decreases at a steady rate. On the right we have a bad curve, it is stepped and a lot less smooth.
Why is this bad?
So, if you have a stepped curve like the bad one on the right, it means going from 2 categories to 3 categories is mundane and boring for the user, because almost everybody's choice of country in the second stage will be accepted in the third, which is little fun. Then after that, you drop from 30 to 3, meaning you have to sift through 30 possible countries just to find one of the 10% that are accepted. It makes the quiz a lot more difficult and laborious, which results in a more boring game in my opinion.
The resulting curves we end up with in the final quiz are generally nice. For example, here are 24 different curves from 6 randomly generated games:
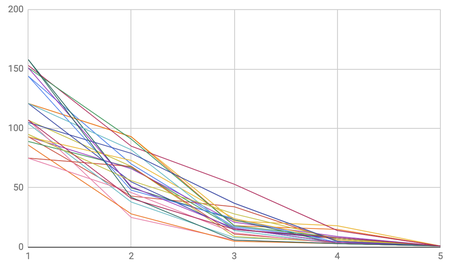
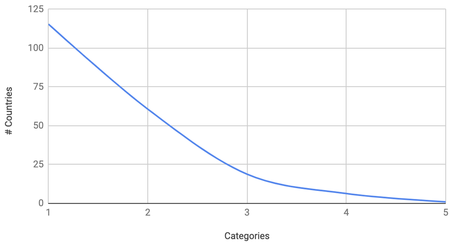
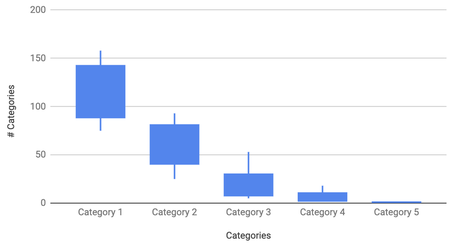
The general shape is clear, but perhaps there are too many lines. Let us draw a mean average curve, as well as a candlestick graph with the minimum, maximum and the values 1 standard deviation either side of the mean. This demonstrates the extremities of the sample data, as well as the most common values.
Adding Special Cases
Although the basic algorithm does the main job, there are ways we can improve it. Here are some the sepcial cases added in to improve the randomness:
- Category groups were created which combine together categories of a similar type into groups, and then we limit to one category per group per set of categories. This fulfils #3 above, since "contains K", "contains E", "contains N" etc... are all part of the same group, so if "contains K" gets selected, then we disallow any other category in that group to be selected in the same set of 5. This ensures greater variation in the categories selected.
Examples of groups, using ? as a placeholder:- with ? on their national flag
- that contain the letter ?
- that are ? letters long
- that border ?
- with more/fewer than ? million people
- A simple check, which might not be obvious, is to ensure the 4 final countries are actually different. In the original algorithm, there's nothing to prevent this, and although it's unlikely to happen, it's still important to prevent it from happening for sure.
- We also use the category groups to ensure each starting clue is different. The first clue of each colour is displayed when you load the quiz, and if they were all "with
on their flag", it might discourage a user as it might seem like a boring quiz. So we not only ensure each of these 4 starting categories are different, we also make sure they're not in the same group! - Another special addition is that the second category must be at least 70% of the original mean value. I mentioned before that the first category must be at least the mean to ensure there is a large starting number of countries, well to ensure the second category doesn't suddenly drop to 10 or something, we place a minimum so that the first two categories combined must be at least 0.7 * the mean value, so this way the "curve" I mentioned before continues to look and feel nice and approachable when playing the quiz.
So as you can see, we add several extra conditions to ensure the quiz looks and feels good when playing it.
Adding Fallbacks
So now we have a quiz which is randomized, feels good and also has special cases to ensure the quiz doesn't look bad or boring, satisfying all the requirements I wanted from it. However we're not quite done with the algorithm yet. After all, with these extra conditions it is possible that picking a country might result in no possible outcome.
For example, if your first 3 countries picked are France, China and Egypt. Then it may be possible that picking something like India may be impossible with the existing 3 category groups taken out, and so we need a way to detect this, and to try again to ensure that a user is never "waiting" for the quiz to load.
- The first check is simply an iteration check. Every time we check a category, we increase the total iterations by 1. If this number exceeds 2000 (roughly 0.01s of load time) then we abort the current country and try a new one. This ensures the algorithm never gets stuck in an infinite loop.
- The next check is a localised iteration check. This is the number of iterations since the last new category added. So, if we already have 4 categories and we're now going to find the 5th and final category. If there's, say, 10 possible categories remaining, then after 20 (2 * number remaining) attempts, if we still haven't found a category which works, we remove the last successful category and go back a step. So in this case we would jump back to 3 categories.
The logic here is that, if you reach this limit it is likely the algorithm is struggling to find another category which works, and so maybe there doesn't exist a valid one. So if we remove the last category accepted, then we widen the range of possibilities and can keep trying without aborting the whole process. - The final check we do is that, if the final category selected results in at least 2 matching countries, then it's likely the categories chosen aren't specific enough and have captured too many answers. To solve this, we remove the 4th and the 3rd category selected, going back to just the first 2 to try again without resulting in duplicates.
Formatting as a JetPunk Quiz
So we now have a complete algorithm and process, we just need to make it something JetPunk can understand. The data we are given back from the algorithm for each set of 5 is the 5 selected categories in order, and the selected country. From this we generate:
The Numbers
This is the easiest part to generate, since we just find the intersection of each category in turn with the remaining countries, and then count how many there are. This returns a list of 5 numbers in order, corresponding to each category.
The Typeins
You may have noticed the quiz accepts all typeins standard on JetPunk, thankfully the answers are all countries and so they all have automatic typeins. This means we just need to perform the same process that a normal quiz does to generate automatic typeins. We then have to combine every typein of each possible country for each of the 5 categories, resulting in a list of 5 lists of typeins, which is something JetPunk can understand.
Now we have the data, we just need to update the quiz. The quiz itself is already setup with dummy data in the categories column, the numbers column and on the grid itself. This is good as it means all the triggers for hiding cells and so on are all setup ready.
The steps needed is to replace the column values with the category name (either "Countries " + category name or "... " + category name as mentioned before to retain linguistic style). Then we add the typeins to each answer as needed. The final step is to update the grid cells themself, since we have to mimic the processes usually performed by the quiz editor, which is a rather complex part of JetPunk I might add.
After all this, we finally have a quiz which can be drawn and displayed to the user!
The Results
The resulting quiz has been largely succesful, and having been featured through nominations today, it appears as though it will continue to do well in the future.
I am really happy with how the quiz turned out, and the fact it works so fast as well. This was a major concern I had initially, that the quiz would be slow to run and so users would be sat waiting for the quiz to load, but thankfully that hasn't happened.
I am also pleased with the randomness. Overall there is enough randomness involved that every user will have an entirely unique experience, while still ensuring every country has a possible solution. I plan to work out just how many possible combinations there are, but I have not done so yet. However, I believe there are enough that every game of 4 sets will be different, since even if two users get the same 4 countries, which is a 1 in 59 million chance disregarding multiple attempts of finding a country, then their games could still have different results since many countries have multiple valid sets of 5 categories.
If people request it, I can do a follow up blog with as much of the maths behind this as possible, though it will certainly take some time to prepare!
For users, the typeins are exactly what they would expect. Any typein from any valid country is accepted. The algorithm only provided country names, which had to be converted to typeins, otherwise the quiz would not know which countries to accept as answers.
That would be very useful!
2. Go to Step 3, set typeins from Auto to Custom (this means changes in Step 2 will not affect them)
3. Go back to Step 2, change the text to be a checkmark (it's a normal unicode character)
This will do what you want.